Trong bài viết Cập nhật 2026 mới nhất, Tuấn có nhắc tới sự trỗi dậy và phát triển chóng mặt của AI trong 1-2 năm gần đây. Mặc dù không hiểu sâu về cách AI thu thập và xử lý dữ liệu từ môi trường xung quanh nhưng dựa vào các bài cảnh báo và than vãn của các website lớn và tình cảnh mà Tuấn đang gặp phải thì AI crawler có thể là một cơn đau đầu đối với bạn.
Vấn đề của các website lớn
CodeBerg, một website lưu trữ code tương tự như GitHub liên tục gặp vấn đề performance do AI gây ra. Mục đích của crawler AI? Thu thập code để huấn luyện cho các mô hình AI.
Cloudflare cũng từng có bài viết chỉ ra rằng bây giờ là thời của AI agent bot. Fastly cũng có một report khá chi tiết về vấn đề này. Nói ngắn gọn rằng, AI bot đang làm tăng tải hệ thống, hao hụt băng thông (có thể tính bằng tiền núi) và làm sai lệch đi thống kê, dự báo truy cập trong phễu marketing của bạn.
Một vấn đề thường gặp cho các loại traffic từ AI bot. Bọn này không đọc và không quan tâm tới tập tin
robots.txtcủa chủ website đặt ra như các crawler truyền thống. Vì vậy không có cách chặn hữu hiệu nào cho các loại AI crawler này. Source
Vấn đề của Tuấn
Khoảng 1-2 năm gần đây Tuấn có host các “alternative frontend” như RedLib, Rimgo hay SearXNG để phục vụ mục đích cá nhân và cho cả cộng đồng. Bằng một cách nào đó thì các website này được lọt vào “mắt xanh” của một vài cá nhân / tổ chức có nhu cầu thu thập dữ liệu để huấn luyện AI của họ.
Lợi ích, fame đâu thì chưa thấy nhưng server đóng vai trò proxy của Tuấn ở Việt Nam đã ngoắc ngoải do không đủ CPU để xử lý. Đây là điều khá bất ngờ vì nếu chỉ thực hiện proxy đúng nghĩa thì vài triệu request một ngày chắc chưa xi nhê gì. Cho tới khi Tuấn xem thống kê DNS query trên Cloudflare thì mới bàng hoàng…
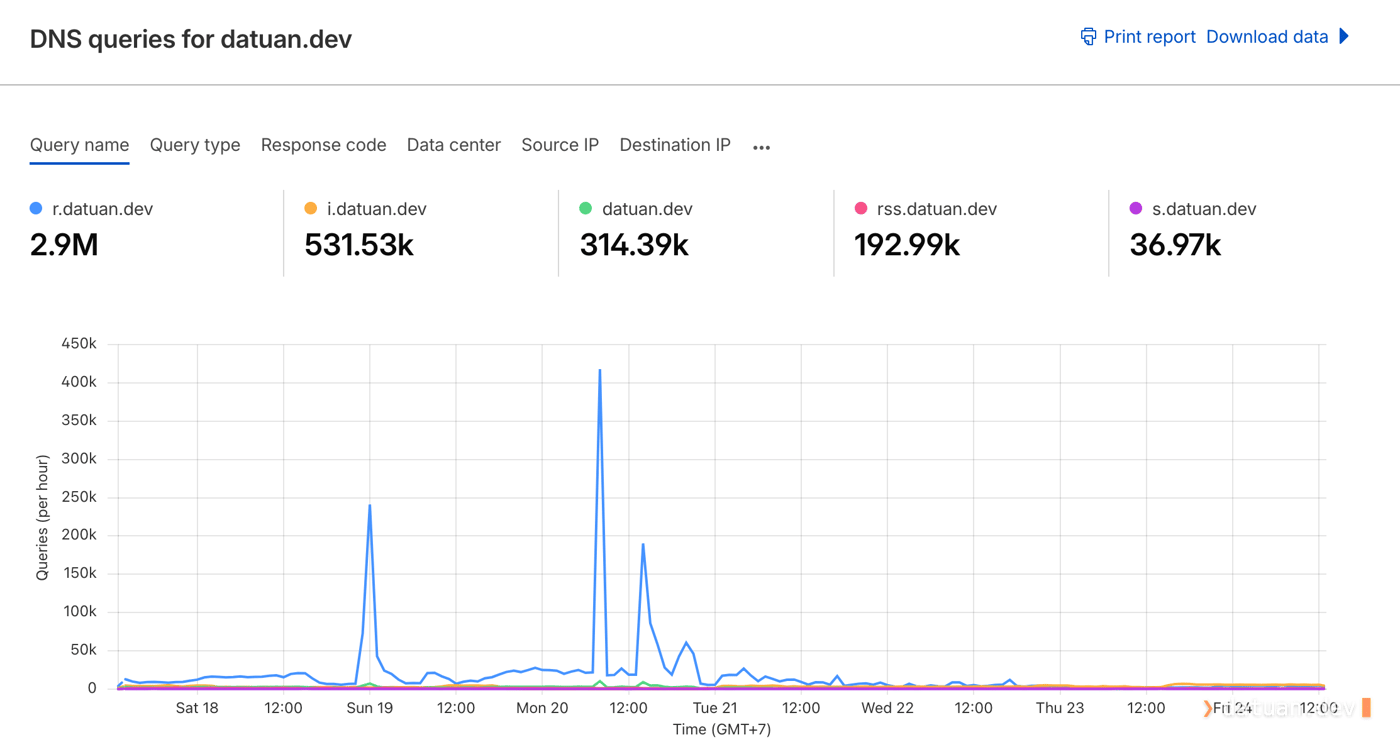
Lật đật thử block theo quốc gia, block top IP gọi nhiều mà không thể hạn chế được vấn đề, Tuấn buộc phải chuyển qua sử dụng Cloudflare proxy (đám mây màu cam 🍊) để đảm bảo các website vẫn hoạt động bình thường và không ảnh hưởng đến các service khác của Tuấn.
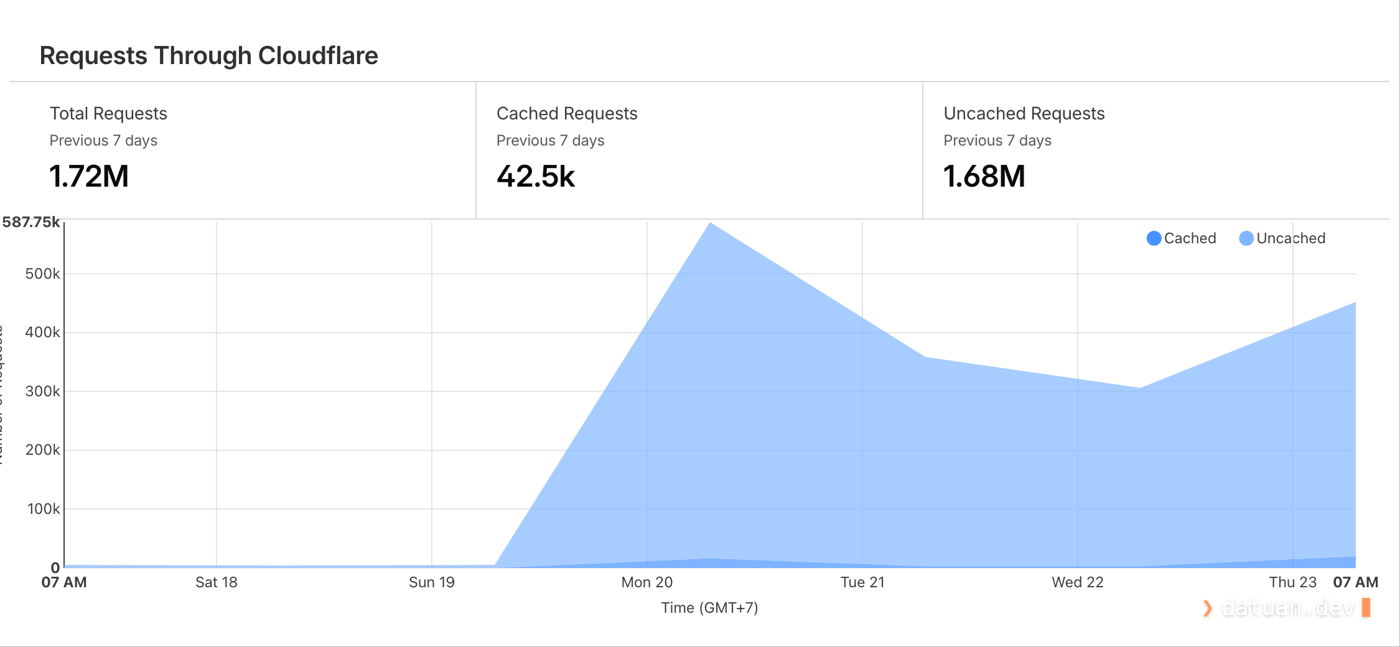
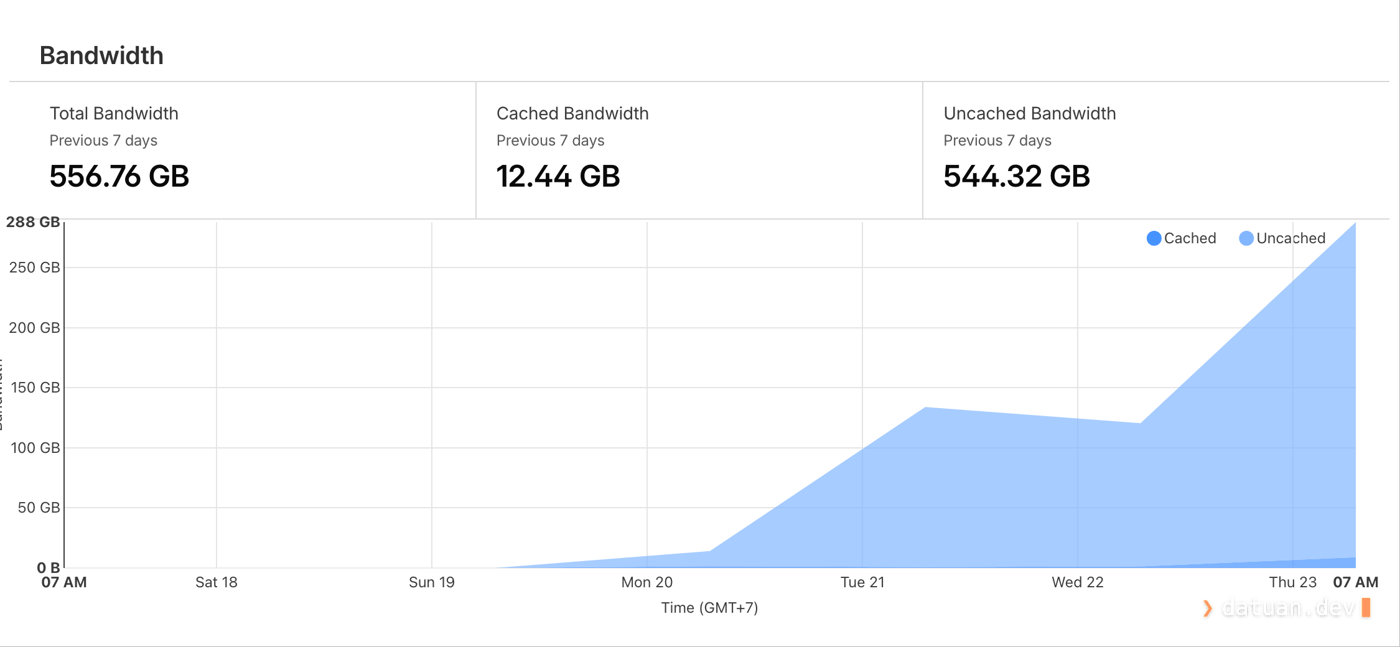
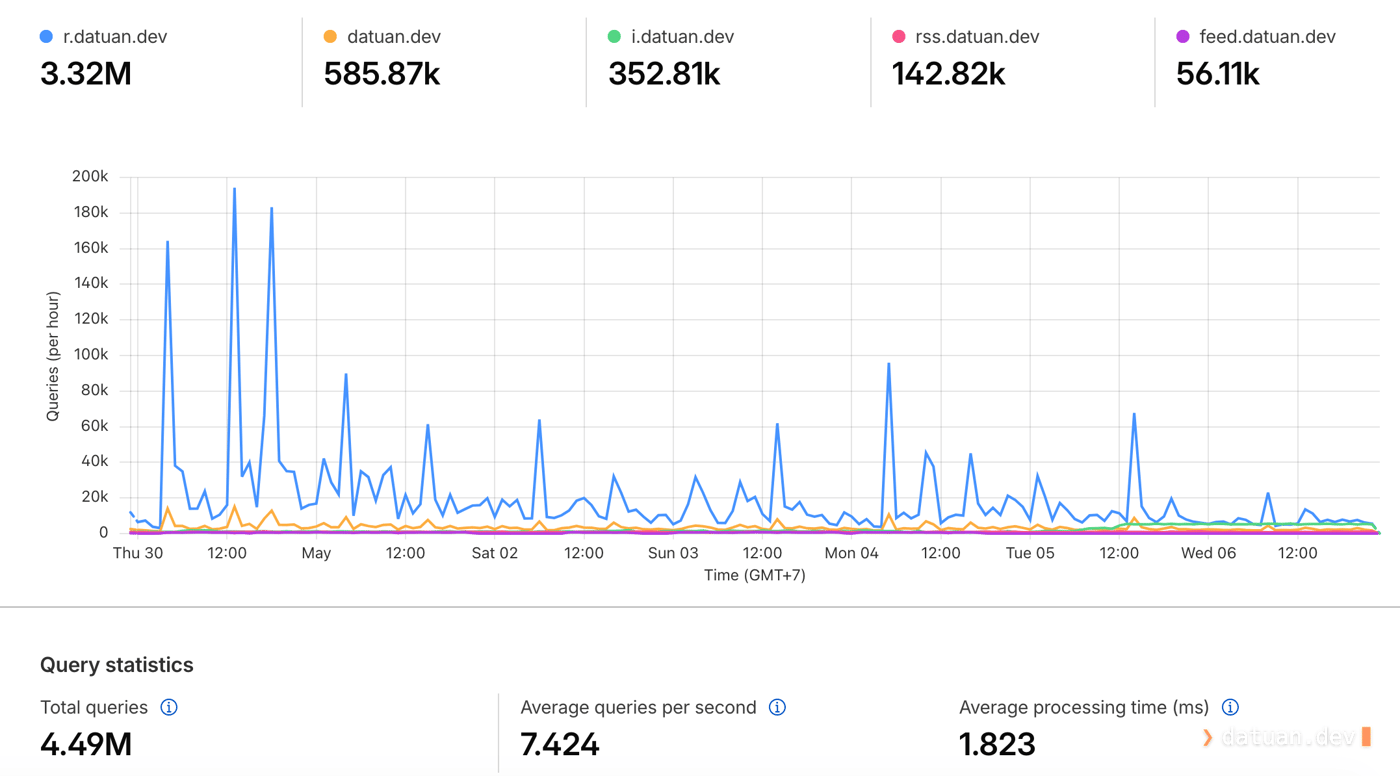
Thực tế sau khi đã chạy qua Cloudflare hoàn toàn, các request từ AI crawler vẫn rất khó để xử lý vì đây là request từ browser thật do các AI agent điều khiển, kết nối từ các IP dân cư như một người sử dụng bình thường. Cho tới hiện tại sau 2 tuần thì các website của Tuấn vẫn được “ghé thăm” rất nhiệt tình và ổn định.
Các câu hỏi tại sao
Tại sao lại sử dụng “Alternate frontend”?
Mục đích đơn giản: tính riêng tư. Tưởng tượng bạn truy cập vào Reddit, bạn phải tải tất cả các tracking script/pixel, tất cả các quảng cáo, đồng ý với quy định sử dụng của Reddit. “Instance” RedLib của Tuấn đứng ra làm trung gian, Reddit chỉ biết Tuấn truy cập tới Reddit, còn lại các thông tin về người dùng thì Reddit không thể lấy được.
Được cái nữa là RedLib sẽ không có tracking pixel, không có quảng cáo, HTML/CSS đơn giản giúp tốc độ tải trang nhanhh hơn nhiều.
Tại sao không sử dụng Cloudflare ngay từ đầu?
Vì vấn đề “privacy”, nếu request chỉ từ người dùng gửi đến Tuấn thì chỉ Tuấn mới biết được. Và nếu không có log lại (thật sự là vậy) thì các request này sẽ gần như hoàn toàn nặc danh, đảm bảo tính riêng tư cho bạn.
Khi request đi qua Cloudflare thì đã có thêm 1 bên thứ ba tham gia luân chuyển các request này. Chúng ta thật sự không biết Cloudflare sẽ làm gì, đọc được gì đối với các dữ liệu này.
Tại sao lại khó chặn?
Request được tạo bằng AI rất khó phát hiện bằng cách thông thường vì thậm chí AI có thể tạo ra một session, điều khi chuột và bàn phím để bắt chước hành động của con người. Bạn hãy nhìn nhanh vào request này và đoán xem đây là request thật hay không?

Tuy nhiên nếu nhìn kĩ hơn nữa bạn sẽ thấy các kết nối của AI mặc dù có gắng “spoof” User-Agent nhưng vẫn sử dụng những kết nối đơn giản như HTTP/1.1 mà theo Tuấn biết trình duyệt đã không còn chủ động sử dụng nữa.
Tuấn handle lượng request này như thế nào?
Nhờ sử dụng Kubernetes kèm với autoscaling ở mức pod và node nên hiện tại các website vẫn hoạt động khá là ổn định. Hehe :)